
At work, I use Windows Vista Ultimate Edition. I tried to install Vista SP1 on my computer yesterday. I created a restore point, just in case something went badly, and started the install. Here’s the error message that I got:

Apparently, Vista SP1 cannot install on my machine, because I’ve got too many language packs installed. Fine, I can understand that. But what I don’t understand is why Microsoft itself kept tagging the extra language packs as “Important Updates”, basically shoving them down my throat and forcing me to install them in the first place. Don’t believe me? Hang on, I’ll give you proof of it below.
I started to remove the language packs, and the uninstall process itself is just horrible. You cannot remove more than one language pack at a time, and it takes at least 10 minutes to do it. Try it yourselves and see. It’s a three-step process. You run the uninstaller from the Control Panel, it takes a few minutes for that, then you’re prompted to reboot, you do so, it takes a few more minutes for the second step, then reboots and runs the third step, which takes the longest. It’s insanely frustrating and a big waste of time. I’m hard-pressed to think Microsoft couldn’t have come up with a better and faster way to install/uninstall language packs.
I had about 7-8 extra languages installed (other than the standard EN/FR/IT/JP). I only did it because Windows wouldn’t quit bugging me to update it by installing the language packs in the first place, and now I find I have to waste more than an hour of my time uninstalling them after having already wasted more than an hour installing them a few months ago. Thanks, Microsoft! Increased productivity my foot…
I uninstalled a few of them yesterday, and here’s the message that I got from Windows after doing that:
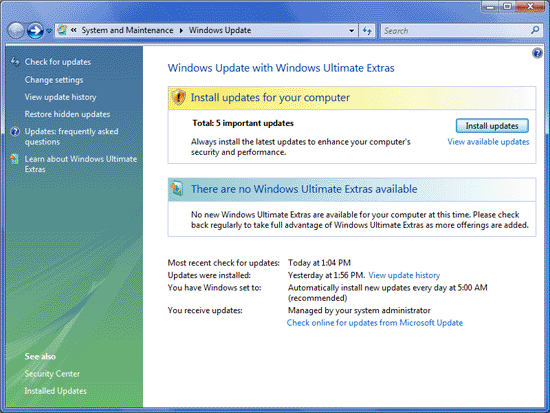
See those 5 important updates tagged with yellow, that Windows advises me to install in order to “enhance my computer’s security and performance”. That’s Microsoft-speak for “waste your time and decrease your computer’s performance”. Guess what they are?
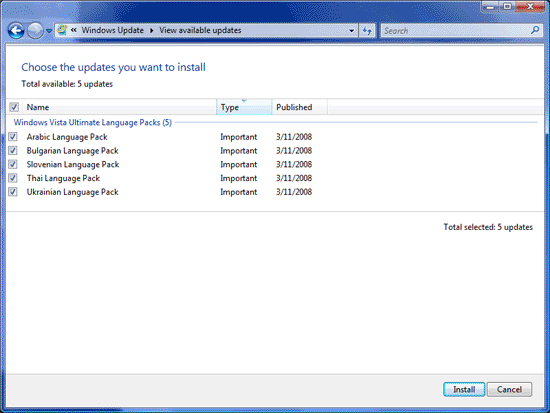
As you can see, it’s the very five language packs that I uninstalled. Windows wants me to install them right back, just so I can’t upgrade to SP1. Isn’t that grand? Don’t you just love Microsoft for their obvious programming logic?
That’s exactly the same type of message I kept getting from Windows before I installed the damned things in the first place. I only installed them so Windows would leave me alone. I guess that won’t happen any time soon, because I now see the same “Available Updates” icon in the taskbar, glaring at me, nagging me to install the stupid language packs. Do you see it below? It’s the blue icon with some sort of orange satellite flying around it.

I only hope Vista SP1 will fix this annoying behavior, but somehow I doubt it. I have a feeling I’m going to have to revert to an earlier system restore point, which would be a real shame, but then again, it would be just what I’d expect from Microsoft.




{kind=link}
{kind=link}
{kind=link}
{kind=link}