
I’ve been using Photoshop since the late 1990s and Lightroom since its launch in 2007. I’ve been a user of Adobe software for some time, and have owned various software packages from them since that time. But in recent years, I’ve begun to be repulsed more and more by their greedy grip on their users. Their move to subscription-based software was the beginning of my discontent, which was only furthered by their constant attempts to constantly monitor what we do with their software and how we use our computers. I know of no other software company that does this so much, and I find it despicable. I think what they’re doing is a clear invasion of user privacy. Some might say it’s benign, that they’re only trying to keep track of their software licenses, but when you find out that they make most of their money with a suite of services they call Experience Cloud, where they offer “AI-driven solutions for marketing, analytics, advertising and e-commerce”, you get the sense that we’re the guinea pigs for their solutions, and their many “helper” applications that are supposed to only monitor software licenses are likely doing a lot more than that on our computers.
I am also a Mac owner, and in stark contrast to Apple’s constant marketing-speak about user privacy, they never mention Adobe’s many applications that are constantly talking back to the Adobe servers, and they never go into the details of what the many Adobe helper applications actually do on our computers.
At best, the many “helper” applications that get put onto your computer when you install Adobe software can be called sloppy programming, and at worst, you have to wonder exactly what they’re doing with each and every one of those pieces of software under the guise of “keeping Adobe applications up-to-date” and “verifying the status of your Adobe licenses”. Most people probably assume those apps are the various components of the Creative Cloud suite and even though they’re numerous and they can probably tell those apps are in constant communication with Adobe, they choose to tolerate them.
I know things may be different on Windows, where software gets installed in multiple places, but on Macs, applications are and have always been packaged into single files that contain all that a piece of software needs in order to work. Even Microsoft Office on the Mac functioned this way and only used one additional piece of auto-update software to make sure everything stayed that way, and after it moved to the App Store, even that went away. They let Apple handle all their updates now.
Not so with Adobe… They have to be “special”. They have to stick their tentacles everywhere on your computer, doing and monitoring who knows what. I absolutely hate the fact that their Creative Cloud software has to run all the time and talk to their servers all the time, just so I can use their software occasionally. I find it abusive and overreaching and questionable, but for some reason, we’ve chosen to go along with it because we want to use the software.
Have a look at what gets installed with their Photography Plan, where only two apps should be present.

You of course will get Creative Cloud, even if you don’t want it, with its many little apps that invade your computer. Then you get Adobe Lightroom CC, the app that hardcore Lightroom users never asked for and don’t want, because all we really want is Lightroom Classic. You then also get Photoshop, which I might use to create a logo once or twice a year, and I infrequently use to blend different frames together into a single photograph (for focus stacking). If that functionality were offered in Lightroom, I’d barely need to open Photoshop. It’s overkill for me.
Let’s see what we get with Creative Cloud, because that’s the crux of this post. Most people won’t realize that the little red folder called Creative Cloud in the Applications folder isn’t really the whole of it. No, Adobe also puts a lot of helper apps in your Utilities folder.
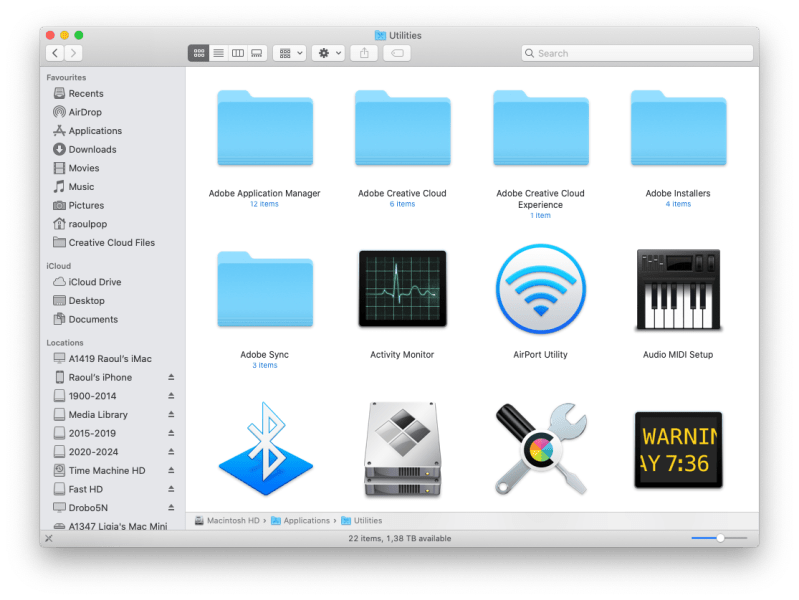
Whether you want them or not, you get Adobe Application Manager, a second Adobe Creative Cloud folder, Adobe Creative Cloud Experience, Adobe Installers and Adobe Sync. Let’s have a look at each of them.
Look at all the “goodies” you get in the Application Manager folder. Yuuuummmy… I didn’t effing ask for all this, Adobe!
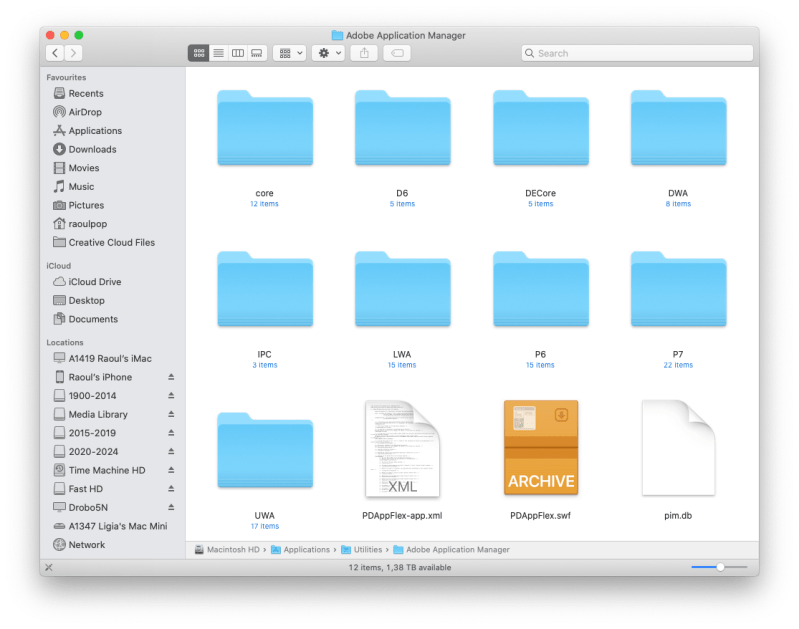
Let’s see what else we get. We get more stuff we never asked for in the Creative Cloud folder.
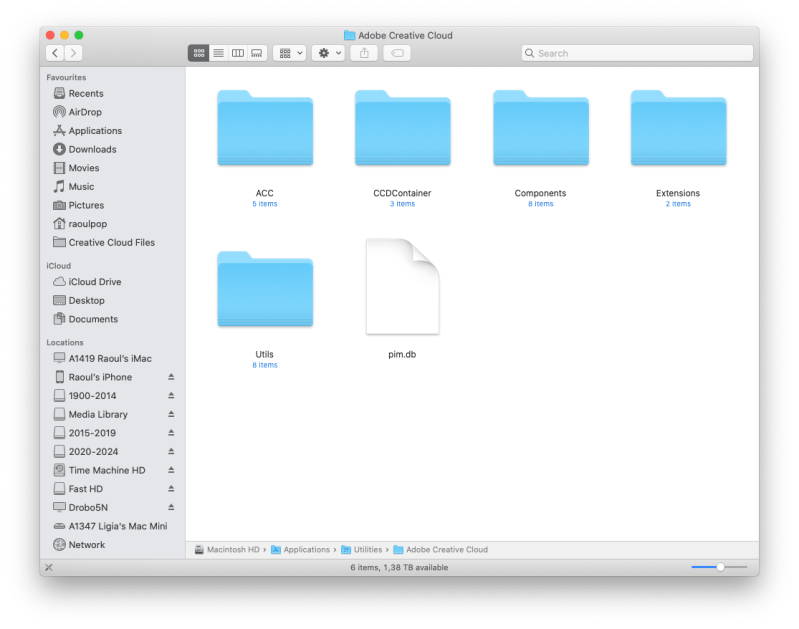
We also get to be part of a Creative Cloud Experience that we never opted into.
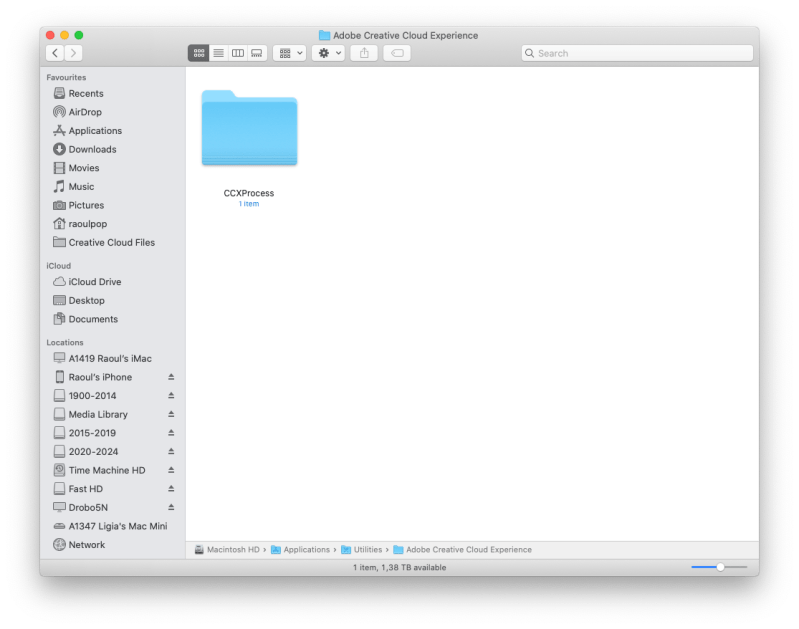
We also get the uninstallers. Fine, okay… although on the Mac, we should simply be able to drag an app from the Applications folder into the Trash (sorry, the Bin) and “bin” done with it.

We also get Adobe Sync, which is another application/service I don’t want and didn’t ask for. Never mind that sometimes it’s stuck on syncing a few photos for weeks on end. I guess it’s thrown in as padding to justify the cost of the subscription plans. “Look, you’re getting the good software, and you’re also getting storage space and a website”… I didn’t ask for it. I just want Lightroom and nothing else!
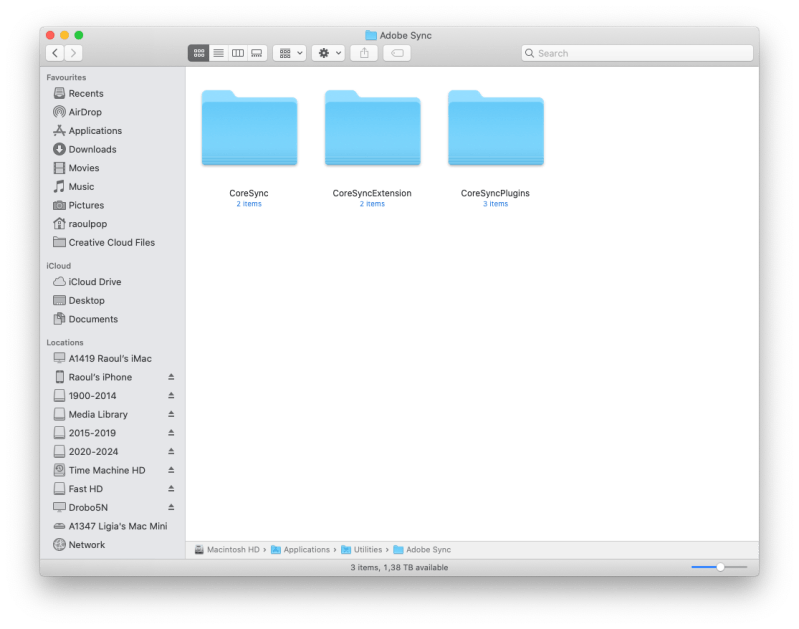
By now you might think we’re done, but no, you also get a special plugin that monitors your online activity, um, “detects whether you have Adobe Application Manager installed. I bet you didn’t know about this little goody from Adobe, did you? It’s called the AdobeAAMDetect.plugin.
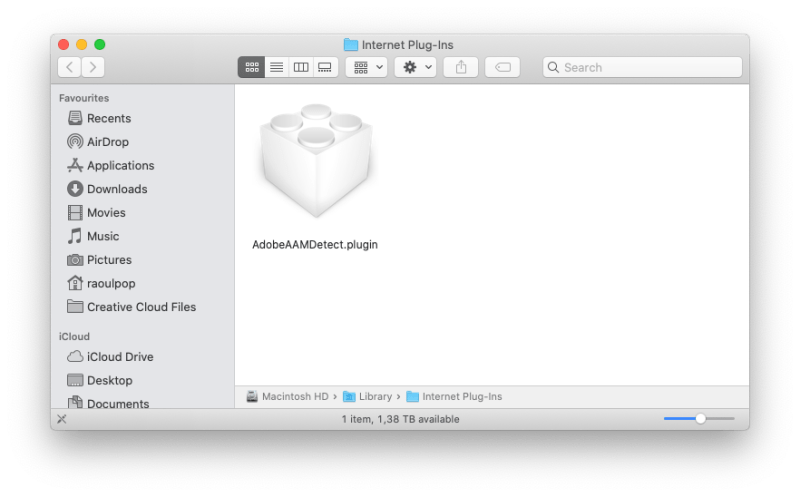
Ostensibly, it’s used to detect whether the Adobe Application Manager is installed onto your computer, but who knows what else it does without looking at its code? All I know is that when I go to my Safari plugins, it’s not openly and transparently listed there. No, it’s hiding in the /Library/Internet Plug-ins/ folder, so you have to know where to look in order to find it. Why? And what else is it doing? Is it monitoring my online activity, just like the apps installed on my computer are monitoring my application usage and who knows what else?
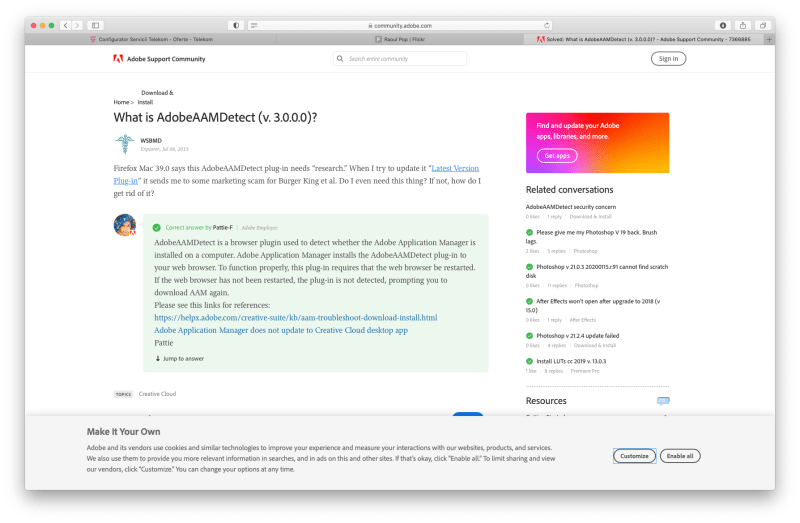
I find all this deeply disgusting, and without opening up each of those apps that Adobe sticks on our computers and looking at the code, we won’t know what they really do. If I didn’t like Lightroom so much, I’d switch to another piece of software in an instant. But I have yet to find a single piece of software that:
- Doesn’t have a subscription plan,
- Lets me easily edit my photos and, this next one is really important to me,
- Lets me easily edit the metadata across all of my photos and update it as needed, and finally,
- Lets me import my catalog from Lightroom while keeping my collections, smart collections and collection sets intact, so I don’t have to sort through hundreds of thousands of photos manually.
After 13 years of using Lightroom, the interface is very familiar. I know exactly where to find what I need, but I sure find Adobe’s business practices despicable and would gladly switch to something else. As far as I’m concerned, they’ve stepped over the line long ago and have been invading the privacy of their users intentionally for years.










